
- Stories
- Brighton SEO 2019: De top 8 sessies volgens Shari & Marijn
Brighton SEO 2019: De top 8 sessies volgens Shari & Marijn
Benieuwd naar de allerbeste sessies tijdens BrightonSEO 2019? Shari en Marijn geven hier een overzicht van de top 8 presentaties tijdens dit event.
Top 4 van Marijn
- How to get a 100% pagespeed score
- Automate your SEO tasks with custom extraction
- Bringing the fun back to SEO with Python
- How to make fake news for links
Top 4 van Shari
- Driving *meaningful* clicks with enriched SERPs
- Restructuring Websites to Improve Indexability
- Living on the Edge: Elevating your SEO toolkit to the CDN
- Crawl budget is dead, please welcome rendering budget
How to get a 100% pagespeed score
Mijn favoriete presentatie was van Polly Pospelova. In deze sessie kwam ze met praktische tips om je paginasnelheid en Lighthouse score te verbeteren.
Zo begon haar presentatie met een kleine disclaimer: Wees je ervan bewust dat de voorwaarden voor een goede Lighthouse score constant veranderen. Zo had de website van haar eigen agency vorig jaar nog een lighthouse score van 100% en was deze, voordat ze de nieuwe optimalisaties doorvoerden, nog maar 56%.
- Het gebruik van http/2 ter verbetering van de pagina snelheid an sich is niet nieuw. Wel legde ze goed uit waarom http/2 zo veel sneller is. Hiermee kan je browser immers alle requests van de server in een keer inladen. Alsof je in een estafette wedstrijd ineens allemaal tegelijk mag rennen, in plaats van om de beurt.
- Optimaliseer je afbeeldingen door lazy loading en ze aan te bieden in het webp formaat. Denk eraan dat je wel altijd een fallback afbeelding formaat instelt voor browsers die nog niet overweg kunnen met webp.
- Maak gebruik van adaptive image markup. Hiermee bied je je afbeeldingen in de backend in meerdere (populaire) formaten aan en kiest de browser uiteindelijk het geschikte formaat. Hierdoor zijn je afbeeldingen altijd perfect geschaald.
- Laad alleen critical Javascript en CSS-bestanden in en laad deze ze hoog mogelijk in de <head> in.
- Maak gebruik van modern JS dit is 300% sneller en 20% kleiner. Ook hierbij is het belangrijk om een fallback in te stellen voor browsers die geen modern JS ondersteunen.
Polly sloot af met het nadrukkelijke advies dat SEOs en developers zich meer dan ooit met elkaar moeten verenigen. Iets dat wij natuurlijk alleen maar kunnen beamen.
Bekijk de volledige presentatie van Polly Pospelova over Lighthouse hier.
Automate your SEO tasks with custom extraction
Max Coupland stelde zichzelf als doel om, door meer te automatiseren, iedereen een dag in de week te besparen. Zijn presentatie ging dan ook in op het automatiseren van SEO taken met Xpath en reguliere expressies (RegEx).
-
Crawl control
De eerste tip die hij gaf was het controleren van crawls. Wanneer je websites met, in zijn geval, 8 miljoen crawlbare URLs moet crawlen met een tool als Screaming Frog, dan is de kans groot dat dit de hele dag duurt. Vaak gaan de meeste resources naar een bijna oneindig aantal combinaties van parameters. Met RegEx kun je gelukkig een aantal handige trucjes toepassen om je crawls te controleren.
Standaard Elementen crawlen met RegEx en Xpath
Met RegEx kun je eenvoudig alle parameter URLs uitsluiten. Dit doe je met de volgende reguliere expressies:
- .*\?.*
- .*\&.*
Ook kun je hiermee een limiet geven aan een maximum aantal te crawlen parameters. De RegEx hiervoor is:
- \?[^&]+([^&]+){2,}
Een andere handige functie om je crawls te controleren is met Xpath. Hiermee kun je bepaalde standaard HTML elementen van een website crawlen.
Het achterhalen van een Xpath doe je door het desbetreffende element te inspecteren met Chrome Dev. Tools. Vervolgens kies je voor Copy Xpath en voeg je deze toe aan je custom extraction binnen een crawler als Screaming Frog.
Hier kun je natuurlijk tal van use cases voor bedenken. Bijv:
-
Crawlen van alle paginas zonder GA tag [](UA-.*?)[]
-
Crawlen van alle paginas met hreflang tags in de <body> i.p.v. de <head> (?m)<body[^>]*>,*?(<link[^>]*h
-
Crawlen van alle paginas met Iframes in de <head> (?m)<body[^>]*>.*?(<link[^>]*hreflang[^>]*>)
Schaalbare keyword research
Op zich was ik al goed aan het opletten door het verhaal van Max. Maar toen hij begon over het automatiseren van keyword research had hij mijn aandacht helemaal.
Door de zoekresultatenpagina van Google te scrapen, ben je in staat om People Also Ask (PAA) zoektermen te scrapen. Elke zoekresultatenpagina heeft namelijk een simpele unieke URL. Dus als je PAA zoektermen van een bepaalde zoekterm wil weten, dan kun je de Xpath kopieren van de <div> waarin de PAA box binnen de zoekresultaten staan. Deze kun je vervolgens toevoegen als custom extraction. Het enige wat je doen nog moet doen is de lijst met Google URLs toevoegen aan Screaming Frog. Gaat dit iets te snel voor je? Check dan dit artikel van Builtvisibible.
Naast het vinden van de juiste keywords is ook het indelen van zoektermen op Search Intent een tijdrovende klus. Door de titles tags van zoekresultaten te scrapen bedacht Max een manier om zoektermen automatisch in te delen op search intent. Met een formule in Google Sheets, die kijkt naar welk type woorden er gebruikt worden in de titles, worden de keywords ingedeeld op commercial, informational of navigational intent. Toont de zoekresutlatenpagina veelal title tags met termen als what, how, why of tips? Dan wordt automatisch een informational intent toegekend. En zijn er termen als buy, order of purchase te zien, dan wordt er automatisch een commercial intent toegevoegd. Hieronder is de formule te zien waar deze variabelen worden ingeschoten.

Bekijk de volledige presentatie van Max Coupland over Custom Extraction hier
Bringing the fun back to SEO with Python
Ook de sessie van Benjamin Goerler was gefocust op het besparen van tijd op je SEO werkzaamheden. Hij begon met te benoemen dat SEO consultants veel te veel tijd kwijt zijn in tools als Excel en Google Spreadsheets. En dat je dit soort werkzaamheden veel efficinter kunt invullen met een programmeertaal als Python.
Het eerste scenario dat Benjamin schetste en waarmee je m.b.v. Python tijd kunt besparen is het analyseren van parameter URLs. Het voordeel van parameters is namelijk dat ze altijd een bepaald patroon vertonen. Parameter URLs bevatten namelijk altijd ?woord= of *woord=.
Met het schrijven van een Python script kun je ervoor zorgen dat crawl data (van bijv. Screaming Frog) wordt opgehaald en dat er automatisch een bestand wordt uitgespuugd met daarin parameter URLs ingedeeld op type parameter.

De tweede use case van Benjamin gaat over het automatisch indelen van keywords. Allereerst moet je een export draaien van je keywords, zoekvolumes en posities. Dit kun je natuurlijk doen met tools als SEMrush, Ahrefs of een andere tool. Vervolgens kun je met behulp van een Python formule en de data uit je SEO tool bijv:
- Zoektermen indelen op categorieen (dames/heren, jurken/schoenen/t-shirts etc.)
- Maandelijks verkeer specifiek naar bepaalde categorieen visualiseren
- Vervolgens gemiddelde posities bepalen van alle zoektermen binnen een categorie
Het gaat wat te ver om in detail uit te leggen met welke formule en op welke manier je deze informatie kunt ontsluiten. Daarvoor zou je programmeertaal Python eerst moeten kennen. Gelukkig deelde Benjamin ook wat recourses om Python te gaan leren.
Bekijk hier de volledige presentatie van Benjamin Goerler. https://www.slideshare.net/bgoerler/bringing-the-fun-back-to-seo-with-python
How to Make Fake News For Links
BrightonSEO zonder goede linkbuilding sessie is als FC Barcelona zonder Messi, daarvoor ga je ook niet naar het stadion. Gelukkig was daar Oliver Brett met zijn sessie.
Hij hield een pleidooi voor fake news (Donald Trump waar ben je?). Nieuws (of een linkbait campagne) hoeft helemaal niet altijd 100% echt te zijn om om er met linkbuilding van te kunnen profiteren.
Een aantal voorbeelden uit de koker van Oliver:
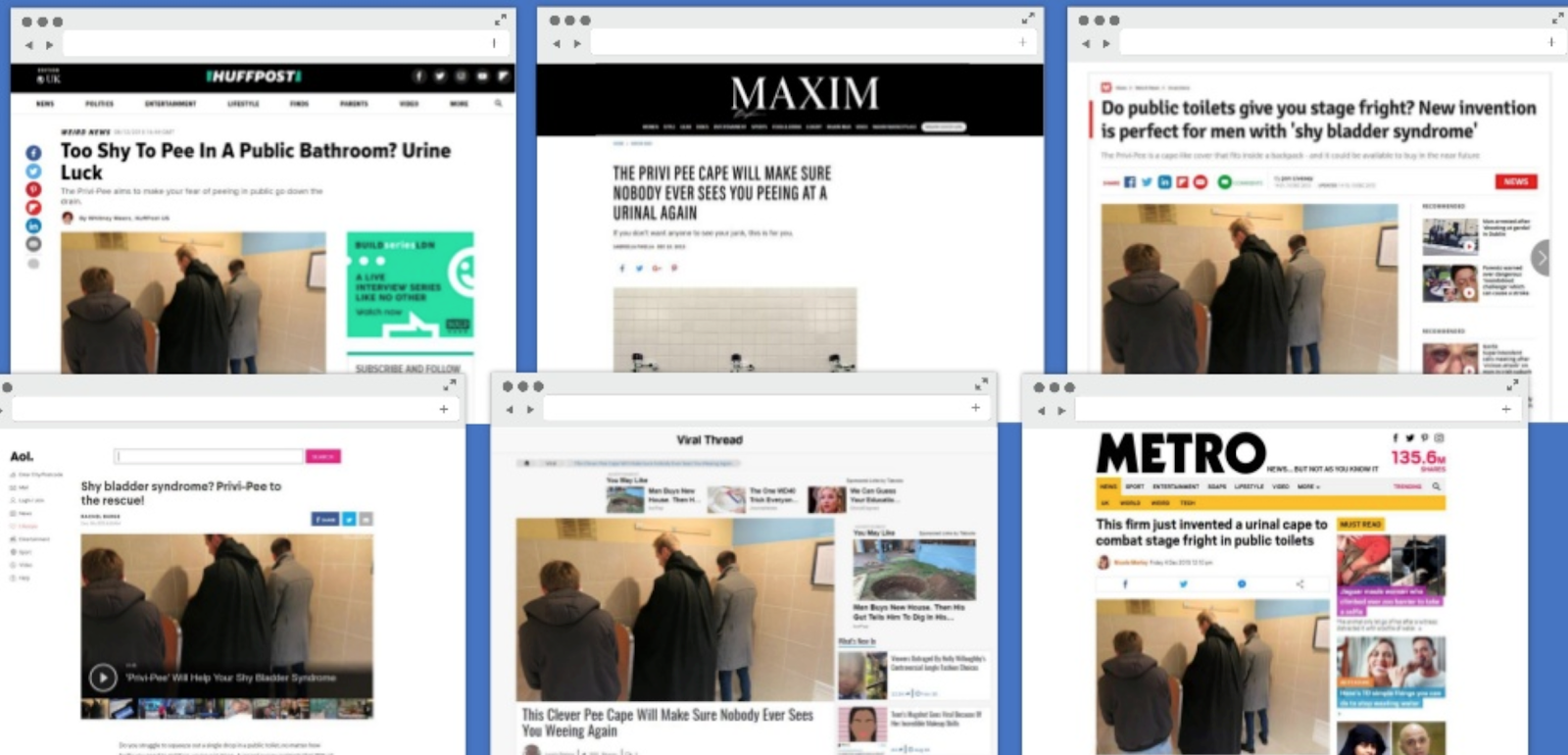
De Pee Cape
Bij wijze van grap bedachten ze een cape voor mannen met plasangst. Deze cape zou ervoor moeten zorgen dat niemand mee kan kijken als je voor een urinoir staat. Onderstaande screenshot laat zien welke publiciteit ze hiermee kregen.
Hondenwebshop
Een andere fake news campagne deden ze voor mode webshop Lyst.com. Waarbij ze, bij wijze van grap, echte honden ging aanbieden op hun webshop. Ook hiermee haalden ze behoorlijk wat publiciteit.
Neppe Star Wars poppen
Voor een andere klant kochten ze een hele partij namaak Star Wars poppen in. Vervolgens plakten ze een ander naampje op het etiket en het nieuws ging viral. Namen die ze hiervoor gebruikten? Tobi-one Kenobi, Fly-Gone Gin en Dennis the Phantom Menace. Hiermee kregen ze publiciteit in o.a. CNN, Mailonline, Vice en zelfs in de krant.
Het Engeland/Rusland shirt
Tijdens het WK van 2016 speelden Engeland en Rusland tegen elkaar. Zoals altijd werden er rellen voorspeld en daar speelden Oliver Brett en zijn team grappig op in. Voor een webshop in ledverlichting kwamen ze met de LED World Cup Comrade Converter Team Swapper T-shirt. Met een knopje kon je de ledverlichting op het shirt laten veranderen in de vlag van Engeland of van Rusland, afhankelijk van in welk gedeelte van de stad je zat. Het shirt werd, vanzelfsprekend, nooit uitgebracht en stond vanaf minuut 1 op out of stock. Wel kreeg de actie de aandacht van een van de grootste nieuwssites wereldwijd, The Guardian.

Oliver sloot zijn sessie af met wat wijze lessen t.a.v. linkbaiting:
- Deze manier van linkbait moet eigenlijk altijd grappig zijn
- Linkbaiting is een snelle en goedkope manier van linkbuilding, mits goed uitgevoerd
- Linkbaiting kun je niet bij elke klant toepassen en vaak niet niet in het begin van een samenwerking.
- Je moet in staat zijn om snel te kunnen handelen.
- Doe het vooral niet te vaak.
Alle linkbaiting campagnes van Oliver en zijn team vind je in zijn presentatie.
Driving *meaningful* clicks with enriched SERPs
Er wordt veel gespeculeerd over de impact van de snippets in de zoekresultaten en daarom sprak deze sessie mij erg aan. De snippets vertonen namelijk direct bovenaan de zoekresultaten een antwoord. Dit neemt een stap weg voor de zoekmachinegebruikers. Izzi Smith deelde met ons dat 62 procent van de zoekresultaten op mobiel resulteert in een 'no-click' door de informatieverschaffing van de snippets. Voor de desktop versie is dit bijna de helft minder, namelijk 34 procent.
Ze vertelde dat haar proces altijd begint met het onderzoeken van de intentie die de mensen hebben als zij het zoekwoord intypen, aangezien er verschillende snippets zijn, zoals: nieuws, merk, lokaal, onderzochte feiten, transactioneel etc. Ze gaf als tip om verschillende intentie zoekwoorden met elkaar te combineren voor een zo compleet mogelijke snippet. De mid- en longtail woorden waren volgens haar het meest geschikt. Daarnaast beveelde ze aan om afbeeldingen te optimaliseren, aangezien deze steeds vaker worden toegevoegd aan de tekst zoekresultaten.
Izzi deelde tevens met ons dat structured data een positieve invloed heeft op het gedrag op de website. In vergelijking tot de standaard snippet leverde een structured data snippet de volgende voordelen op:
- Een verlaging van de bouncerate (-31%)
- Een verhoging van de sessieduur (+23%)
- Een verhoging van het conversieratio (+52%)
Bekijk de volledige presentatie van Izzi Smith hier.
Restructuring Websites to Improve Indexability
Veel websites hebben de uitdaging om het crawl management goed in te richten. Sites die vacatures aanbieden hebben bijvoorbeeld vaak een zoekmachine die de basis is van hun website voor het vinden van vacatures. Daarnaast hebben ze veel verschillende zoekwoorden waar ze op willen ranken, maar ook veel urls. Dit heeft een grote impact op het inrichten van de techniek, zodat het crawl budget zo effectief mogelijk wordt besteed.
Areej AbuAli vertelde over haar samenwerking en aanpak met een klant die beschikt over een vacaturewebsite. Om het aantal paginas die relevant zijn voor de index schaalbaar te maken heeft zij een keyword database opgesteld waarin verschillende zoekwoord volgorde combinaties een regel vormde. Door de regel worden zoekopdrachten zoals: vacature website developer Adwise, website developer vacature Adwise en website developer vacature Adwise als n term gezien. Hierdoor worden duplicate resultaten uitgesloten uit de index. Daarnaast werd er een regel ingesteld met beschikbaarheid en minimaal zoekvolume i.v.m. de grote hoeveelheid keywords. Hierdoor ontstond er uiteindelijk een overzicht met pagina's die dienen te worden gendexeerd.
Bekijk hier de volledige presentatie van Areej AbuAli
Living on the Edge: Elevating your SEO toolkit to the CDN
De sessie van Nils de Moor over CDN vond ik erg interessant, omdat met name snelheid een groot issue is bij veel meertalige websites. CDN, oftewel Content Delivery Network, kent vele voordelen voor SEO. Een van de grootste voordelen is dat CDN de server kan vervangen. Veel internationale websites hebben het probleem dat hun website in het buitenland trager is i.v.m. de locatie van de server. Bij een CDN wordt er gebruik gemaakt van de dichtstbijzijnde server. Hierdoor bespaart het tijd, aangezien de content CDN de content dichter bij de gebruiker brengt. Ook bespaart deze kortere bandwijdte kosten en is een CDN geen zware last op de infrastructuur.
Nils deelde ook dat de volgende technische SEO aspecten allemaal te managen zijn op CDN niveau:
- Hreflang
- Robots.txt
- Redirects
- Security
- Access logs
- Ab testing
Naast de al beschreven voordelen gaf Nils aan dat CDN tevens relevant is voor AB-testing, aangezien dit de Javascript verlaagt ten opzichte van de tools die voornamelijk worden ingezet voor AB-testing op dit moment.
Bekijk de volledige presentatie van Nils de Moor hier.
Crawl Budget is dead, please welcome Rendering Budget
Een van de meest grote onderwerpen binnen SEO is Javascript in combinatie met het crawl- en renderingbudget. Javascript is in vergelijking met HTML lastig te crawlen voor zoekmachines. Volgens Robin Eisenberg is Javascript traag, asynchroon en complex voor zoekmachines. Hij vertelde dat er een directe correlatie is tussen pagina snelheid en crawl volume. Hierdoor kan het zijn dat niet je hele website wordt gendexeerd, waardoor mogelijk niet alle paginas worden getoond in de zoekmachine.
In de eerste golf wordt alleen de statische HTML gendexeerd. Rendering wordt uitgesteld totdat zoekmachines de bronnen gereed hebben om de client side content te renderen. In de tweede golf wordt de Javascript pas gendexeerd.
Robin liet zien dat je de rendering ratio kan uitrekenen door in de zoekmachine het aantal resultaten van de volgende zoekopdrachten door elkaar deelt:
site:www.voorbeeld.nl html/site: www.voorbeeld.nl html-element Javascript-element
Met het rendering ratio kan er worden gemeten hoeveel Javascript content er ontbreekt op de website. Daarnaast gaf hij nog als tip om KPIs op te stellen omtrent Javascript rendering, zoals:
- First Contentful Paint
- Time To Interactive
- Grootte en verzoeken
- Lighthouse scores










Since 2005 - #1 Fullservice Digital Agency '26
